 Principal Investigator: Brad Rittenhouse
Principal Investigator: Brad Rittenhouse
Project Team: Sudeep Agarwal, Taha Merghani, Madison McRoy, Nate Knauf, Sidharth Potdar, and Kevin Kusuma
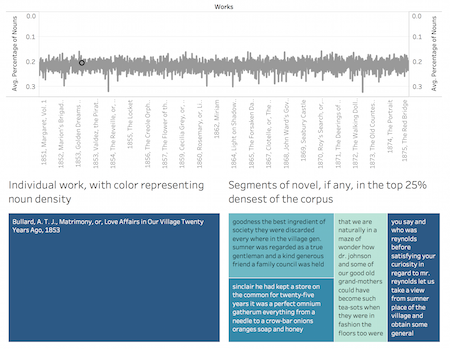
Informationally-dense literature, sometimes referred to as “encyclopedic narrative,” has often been prized by scholars, and afforded a prestigious place in the literary canon. However, these works and the prestige that comes with them tend to be overwhelmingly male: books like Thomas Pynchon’s Gravity’s Rainbow and Herman Melville’s Moby Dick, for instance, assemble knowledge on topics like ballistics and whaling. This project explores methods for agnostically identifying instances of information aggregation across a literary corpus, sidestepping human biases that overvalue data from mathematics and the hard sciences.
Working on the Wright American Fiction corpus, which includes nearly every work of American fiction written between 1850 and 1875, we have developed a curatorial process that points to specific passages where material information—the people, products, and print that proliferated during this period of American history—accretes. Manifested as noun density, this measure allows us to quantify literary data at a suitable level of specificity: it allows us to find writers who are struggling to represent their newly dense material reality aesthetically, but stops short of proscribing specific types of material data. Writers who catalogue whales, like Melville, are counted equally to writers who may concern themselves more with, say, household items.
Moving forward, we hope to refine our algorithm to detect not just the presence of information, but its absence. African-American writers, for instance, often struggled with assembling hereditary information, which was often kept from them, or in representing experiences too traumatic to be told. We are also working on interactive frameworks for visualizing our data and allowing others to explore it.